Урок 5. Пишем парсер каталога товаров на Scrapy / Python

Published: 30 November в 15:47
Всем привет!
Продолжаем серию уроков по разработке парсера на Python.
Сегодня мы перепишем наш парсер с первого урока с использованием фреймворка Scrapy, который позволяет быстро, удобно и качественно создавать серьезные проекты по парсингу, беря на себя значительную часть работы.
В предыдущих уроках: 1) мы написали парсер каталога товаров в файл JSON – видео 2) добавили сохранение результата в Excel-таблицу – видео 3) добавили отправку файлов с результатами в чат Telegram – видео 4) создали небольшого Telegram-бота для получения файлов с результатами парсинга – видео
Шаг 1. Подготовка
Установим библиотеку Scrapy командой:
pip install scrapyСоздадим новый проект под названием lesson5 в текущей директории:
scrapy startproject lesson5 .Создадим паука:
scrapy genspider catalog parsemachine.comСтруктура проекта Scrapy на изображении ниже.
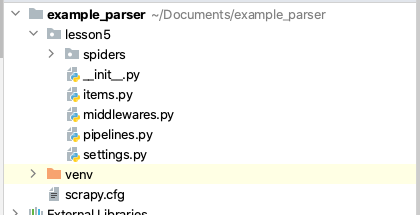
В рамках данного урока мы не рассматриваем items, pipelines и middlewares. Нас интересует только spiders/catalog.py – наш паук. Файл settings.py – это настройки проекта.
Шаг 2. Программирование
Работаем внутри класса паука CatalogSpider.
Зададим переменную pages_count = 10, как и ранее – это номер последней страницы с карточками товаров для сбора.
Переопределим метод start_requests, который вызывается при запуске парсера. Здесь мы будем формировать URL-адреса страниц с карточками товаров и отправлять паука по этим адресам.
def start_requests(self):
for page in range(1, 1 + self.pages_count):
url = f'https://parsemachine.com/sandbox/catalog/?page={page}'
yield scrapy.Request(url, callback=self.parse_pages)
Метод parse_pages, который передается в Request выше, будет собирать ссылки на конкретные товары со страницы. Метод css объекта Response принимает на вход CSS-селектор. Нас интересуют атрибуты href всех тегов a с карточек товаров. Извлекаем все найденные значения и преобразуем полученные значения в URL с помощью метода response.urljoin.
def parse_pages(self, response, **kwargs):
for href in response.css('.product-card .title::attr("href")').extract():
url = response.urljoin(href)
yield scrapy.Request(url, callback=self.parse)
Переходим к написанию обработчика страницы конкретного товара.
Получаем название товара и цену, используя CSS-селекторы #product_name и #product_amount соответственно. Текущий URL получаем через объект запроса, ассоциированный с ответом response. Характеристики получаем, как в первом уроке.
def parse(self, response, **kwargs):
techs = {}
for row in response.css('#characteristics tbody tr'):
cols = row.css('td::text').extract()
techs[cols[0]] = cols[1]
item = {
'url': response.request.url,
'title': response.css('#product_name::text').extract_first('').strip(),
'price': response.css('#product_amount::text').extract_first('').strip(),
'techs': techs,
}
yield item
Шаг 3. Запускаем
Мы будем сохранять результат в файл формата JSON, для этого запускаем наш паук с ключом -O (большая буква O англ.).
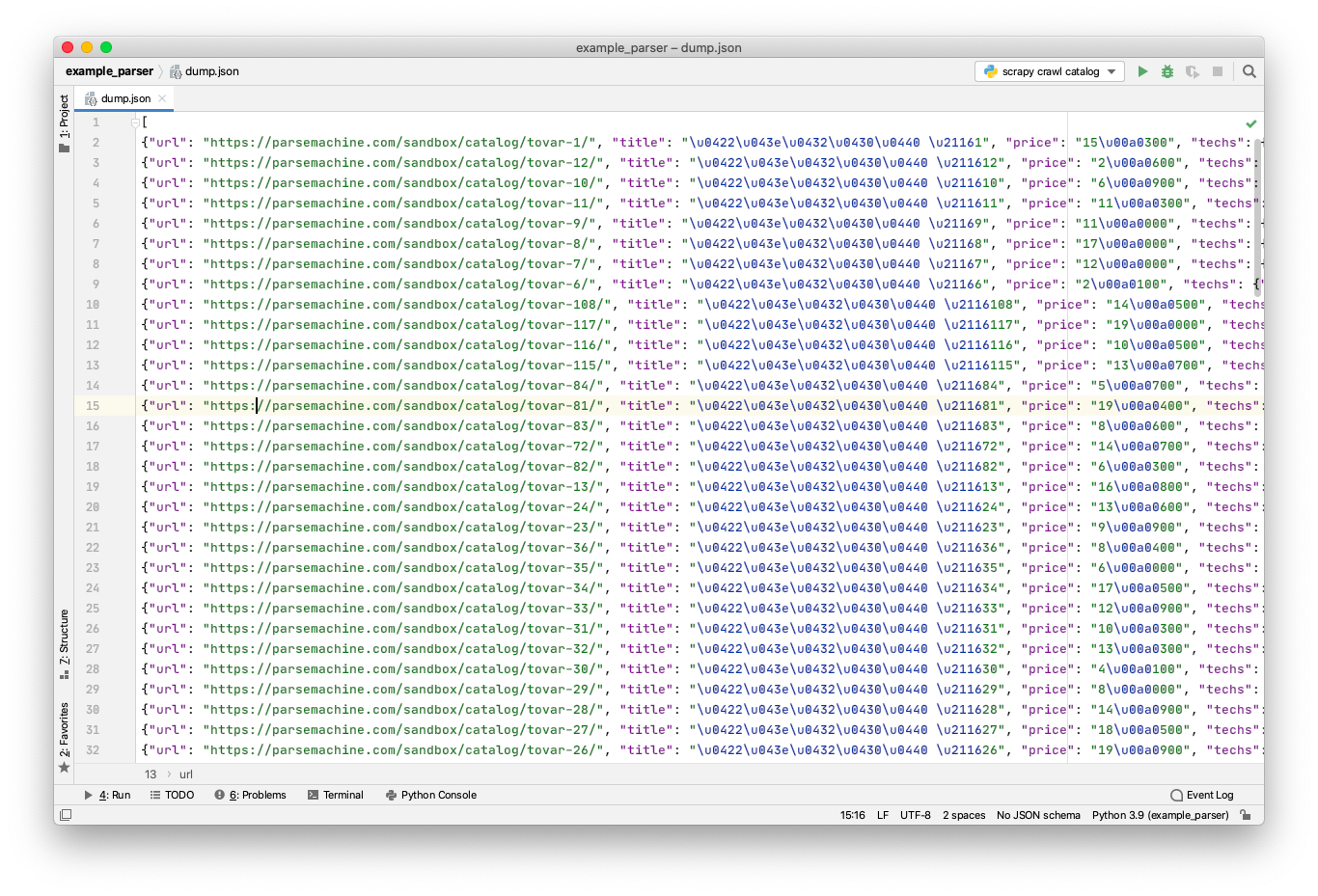
scrapy crawl catalog -O dump.jsonПосле завершения файла у нас появился файл dump.json, открываем и видим результат парсинга. В каждой строке по python-словарю с данными очередного товара
На этом все, спасибо за внимание!
Если у вас возникли какие-то вопросы, можете задать их в комментариях к этой статье или под видео на YouTube. Предлагайте темы следующих уроков.
Спасибо за внимание!