Урок 2. Сохраняем результаты парсинга в Excel-таблицу (Python)

Published: 9 November в 13:28
Всем привет!
Продолжаем серию уроков по разработке парсера на Python. Сегодня мы добавим сохранение результатов парсинга в Excel-таблицу, используя библиотеку xlsxwriter.
В предыдущем уроке мы собирали товары с тестового каталога с помощью библиотек requests и beautifulsoup4. Результат сохраняли в файл формата JSON, а сегодня добавим и в XLSX.
Библиотеки, используемые в данной статье:
1. xlsxwriter – ссылка на документацию.
По любым возникающим в ходе урока вопросам оставляйте комментарии ниже.
Ссылка на полный текст исходного кода находится в конце статьи.
Шаг 1. Подготовка
В дополнение к данным, которые мы собирали в словарь item по каждому товару, добавим URL-адрес:item = {
'name': name,
'amount': amount,
'techs': techs,
# добавялем URL
'url': url,
}
Вынесем для удобства запись в JSON-файл в отдельный метод. Два позиционных аргумента:
1. filename – имя файла Excel-таблицы.
2. data – объект с результатом парсинга, список из данных по каждому товару.
А также именованные аргументы kwargs для передачи в json.dump().
def dump_to_json(filename, data, **kwargs):
kwargs.setdefault('ensure_ascii', False)
kwargs.setdefault('indent', 1)
with open(OUT_FILENAME, 'w') as f:
json.dump(data, f, **kwargs)
В основном коде в функции main() вызываем dump_to_json:
def main():
urls = crawl_products(PAGES_COUNT)
data = parse_products(urls)
# добавляем запись в JSON-фал функцией dump_to_json
dump_to_json(OUT_FILENAME, data)
Подготовка завершена, переходим к записи в Excel.
Шаг 2. Установка зависимостей
Установим библиотеку xlsxwriter командой:pip install xlsxwriterШаг 3. Программирование
Импортируем библиотеку xlsxwriter:
import xslxwriter
Добавим глобальную переменную OUT_XLSX_FILENAME – имя Excel файла.
OUT_XLSX_FILENAME = 'out.xlsx'
Объявим функцию создания Excel файла и записи в него данных:
def dump_to_xlsx(filename, data):
pass
Создадим Excel файл с нашим именем и добавим один лист (worksheet). Запишем в первую строку названия колонок (headers). Затем пройдемся по каждому товару и запишем данные в отдельные строки. Характеристики разделим по колонкам так, чтобы каждая из них была в отдельной колонке. Нам известно, что для всех товаров у нас одни и те же характеристики, поэтому для названия колонок возьмем названия из item['techs'] первого товара. Также перед записью проверим, есть ли товары для записи, если их нет, то функция возвращает None и не создает файл. Полный текст функции приведен ниже:
def dump_to_xlsx(filename, data):
if not len(data):
return None
with xlsxwriter.Workbook(filename) as workbook:
ws = workbook.add_worksheet()
bold = workbook.add_format({'bold': True})
headers = ['Название товара', 'Цена', 'Ссылка']
headers.extend(data[0]['techs'].keys())
for col, h in enumerate(headers):
ws.write_string(0, col, h, cell_format=bold)
for row, item in enumerate(data, start=1):
ws.write_string(row, 0, item['name'])
ws.write_string(row, 1, item['amount'])
ws.write_string(row, 2, item['url'])
for prop_name, prop_value in item['techs'].items():
col = headers.index(prop_name)
ws.write_string(row, col, prop_value)
Итог
Все!
Теперь достаточно вызвать функцию следующий образом для сохранения data в Excel:
dump_to_xlsx(OUT_XLSX_FILENAME, data)После прогона парсека по двум страницам (PAGES_COUNT = 2) видим, что в out.json к каждому товарному теперь добавился url.

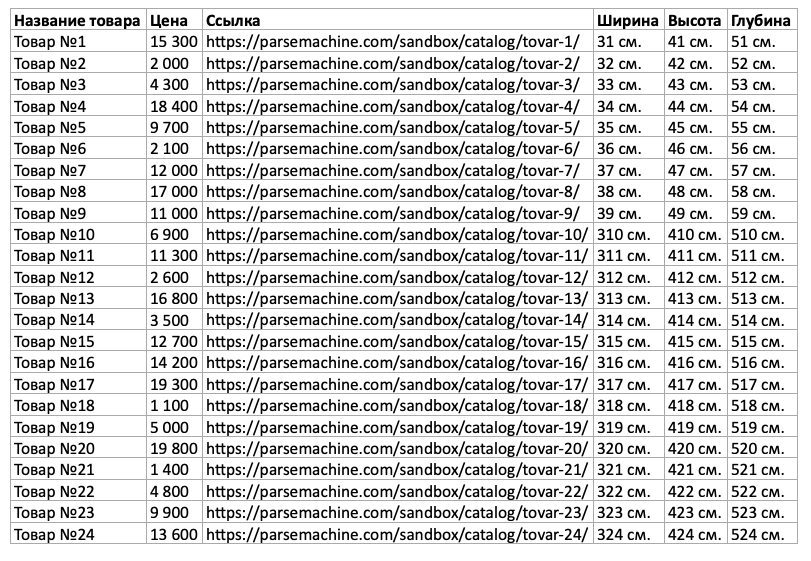
Открываем файл out.xlsx и видим 24 товара, каждая характеристика в отдельной колонке. Первая строка жирным шрифтом. На этом сохранение в Excel завершено.
Ссылка на полный текст исходного кода – catalog.py
Если у вас возникли какие-то вопросы, можете задать их в комментариях к этой статье или под видео на YouTube. Предлагайте темы следующих уроков.
Спасибо за внимание!