Python – Как работать с большими CSV-файлами

Опубликовано: 18 декабря в 20:24
В данной статье рассмотрим кастомизацию административной панели для импорта записей из файла в базу данных.
Шаг 1. Подготовка базы данных
Создадим модель Record с двумя полями name и value, значения которых будут заполняться импортом xlsx-файла. Название нашего приложения – core.
from django.db import models
class Record(models.Model):
class Meta:
verbose_name = 'Запись'
verbose_name_plural = 'Записи'
name = models.CharField(
verbose_name='Название', max_length=200,
)
value = models.CharField(
verbose_name='Значение', max_length=200,
)
def __str__(self):
return str(self.name)
Создадим файлы миграций, применим их:
python manage.py makemigrations
python manage.py migrate
Добавим отображение модели в административной панели:
class RecordAdmin(admin.ModelAdmin):
list_display = ('name', 'value')
admin.site.register(Record, RecordAdmin)
Шаг 2. Кастомизация административной панели
Будем импортировать простой xlsx-файл с двумя колонками, которые будут заполнять значения модели name и value соответственно.

Первым делом добавим форму импорта xlsx-файла в файл core/forms.py:
from django import forms
class XlsxImportForm(forms.Form):
xlsx_file = forms.FileField()
Добавим обработчик, загружающий файл, читающий данные и записывающих их в базу данных:
from django.contrib import admin
from django.shortcuts import redirect, render
from django.urls import path
from openpyxl.reader.excel import load_workbook
from core.forms import XlsxImportForm
from core.models import Record
class RecordAdmin(admin.ModelAdmin):
list_display = ('name', 'value')
change_list_template = 'core/record_change_list.html'
def get_urls(self):
urls = super().get_urls()
# Добавляем URL нашего обработчика импорта.
my_urls = [
path('import-records-from-xlsx/', self.import_records_from_xlsx),
]
return my_urls + urls
def import_records_from_xlsx(self, request):
context = admin.site.each_context(request)
if request.method == 'POST':
xlsx_file = request.FILES['xlsx_file']
workbook = load_workbook(filename=xlsx_file, read_only=True)
worksheet = workbook.active
# Читаем файл построчно и создаем объекты.
records_to_save = []
for row in worksheet.rows:
new_obj = Record(name=row[0].value, value=row[1].value)
records_to_save.append(new_obj)
Record.objects.bulk_create(records_to_save)
self.message_user(request, f'Импортировано строк: {len(records_to_save)}.')
return redirect('admin:core_record_changelist')
context['form'] = XlsxImportForm()
return render(request, 'core/add_records_form.html', context=context)
admin.site.register(Record, RecordAdmin)
Добавим необходимые шаблоны:
core/templates/core/record_change_list.html
{% extends 'admin/change_list.html' %}
{% load admin_list %}
{% block object-tools-items %}
<li>
<a href="import-records-from-xlsx/" class="addlink">Импортировать записи из XLSX</a>
</li>
{% change_list_object_tools %}
{% endblock %}
core/templates/core/add_records_form.html
{% extends 'admin/base_site.html' %}
{% block content %}
<div>
<form action="." method="POST" enctype="multipart/form-data">
{{ form.as_p }}
{% csrf_token %}
<input type="submit" value="Импортировать из XLSX">
</form>
</div>
<br />
{% endblock %}
Шаг 3. Смотрим результат
Видим появление новой кнопки импорта файла:
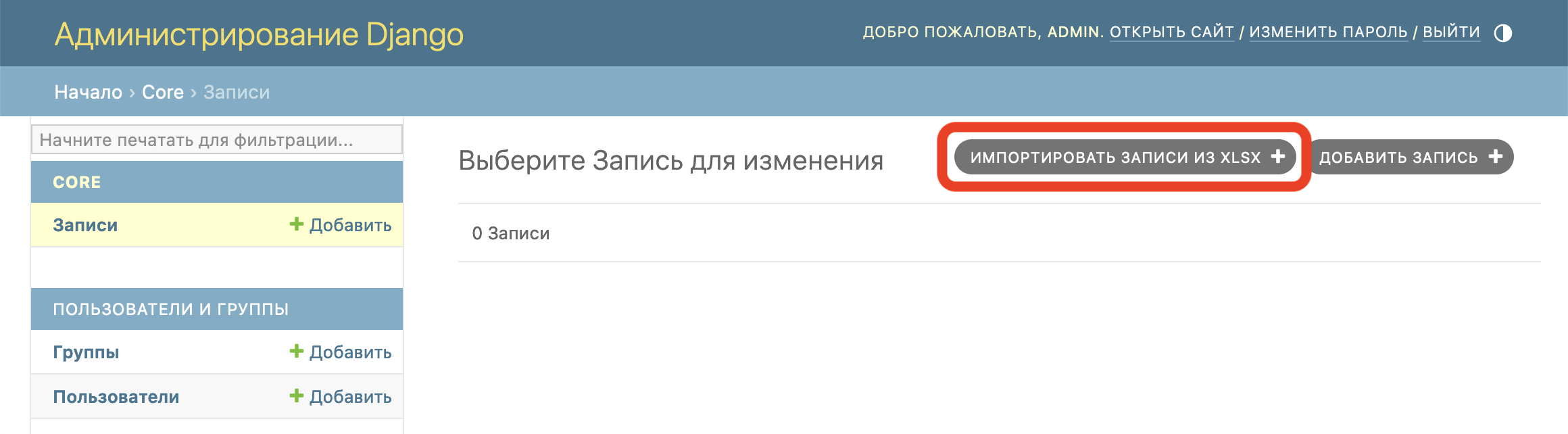
Через форму загружаем файл:
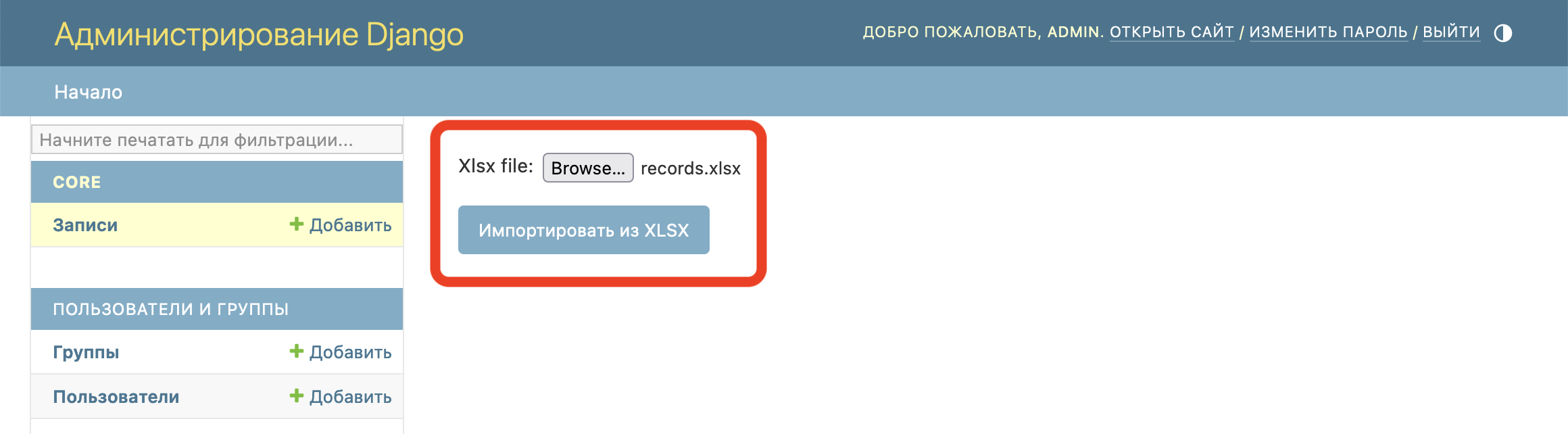
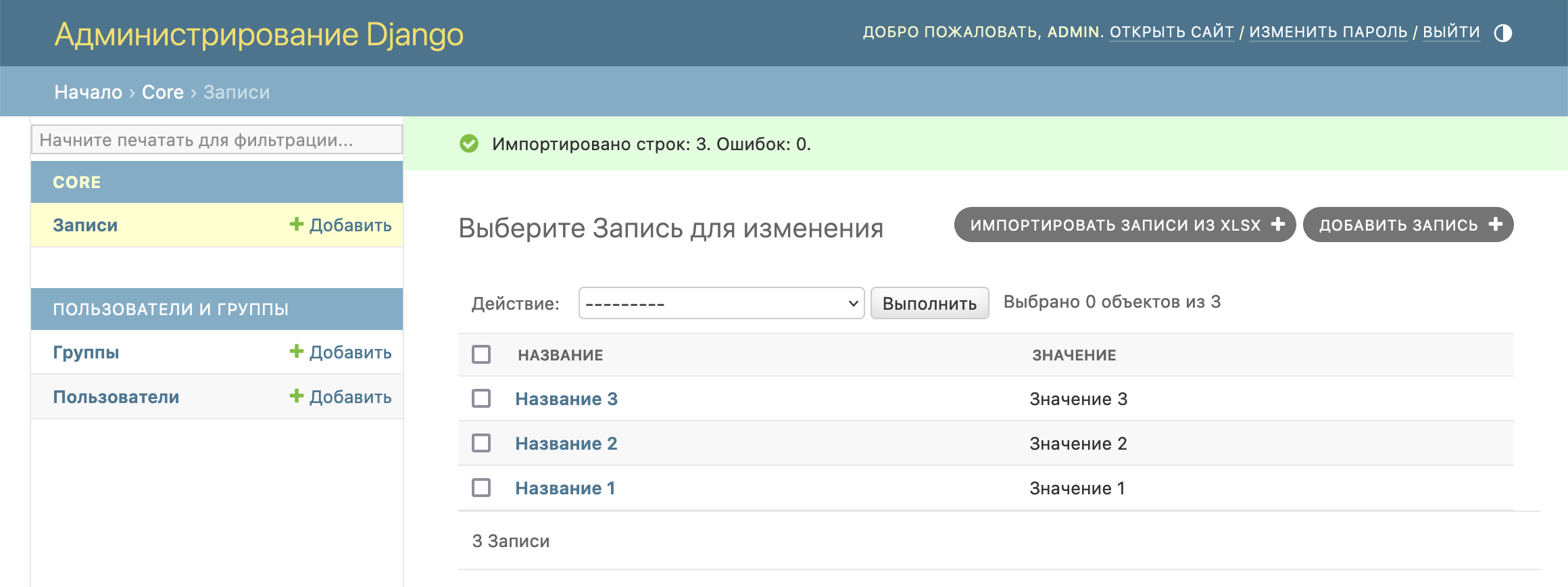
Файл успешно импортирован, записи добавлены:
Выводы
Вот таким простым способом можно добавить импорт записей из файла в базу данных, кастомизируя административную панель.
По вопросам сотрудничества и с иными вопросами обращайтесь по контактам на сайте.